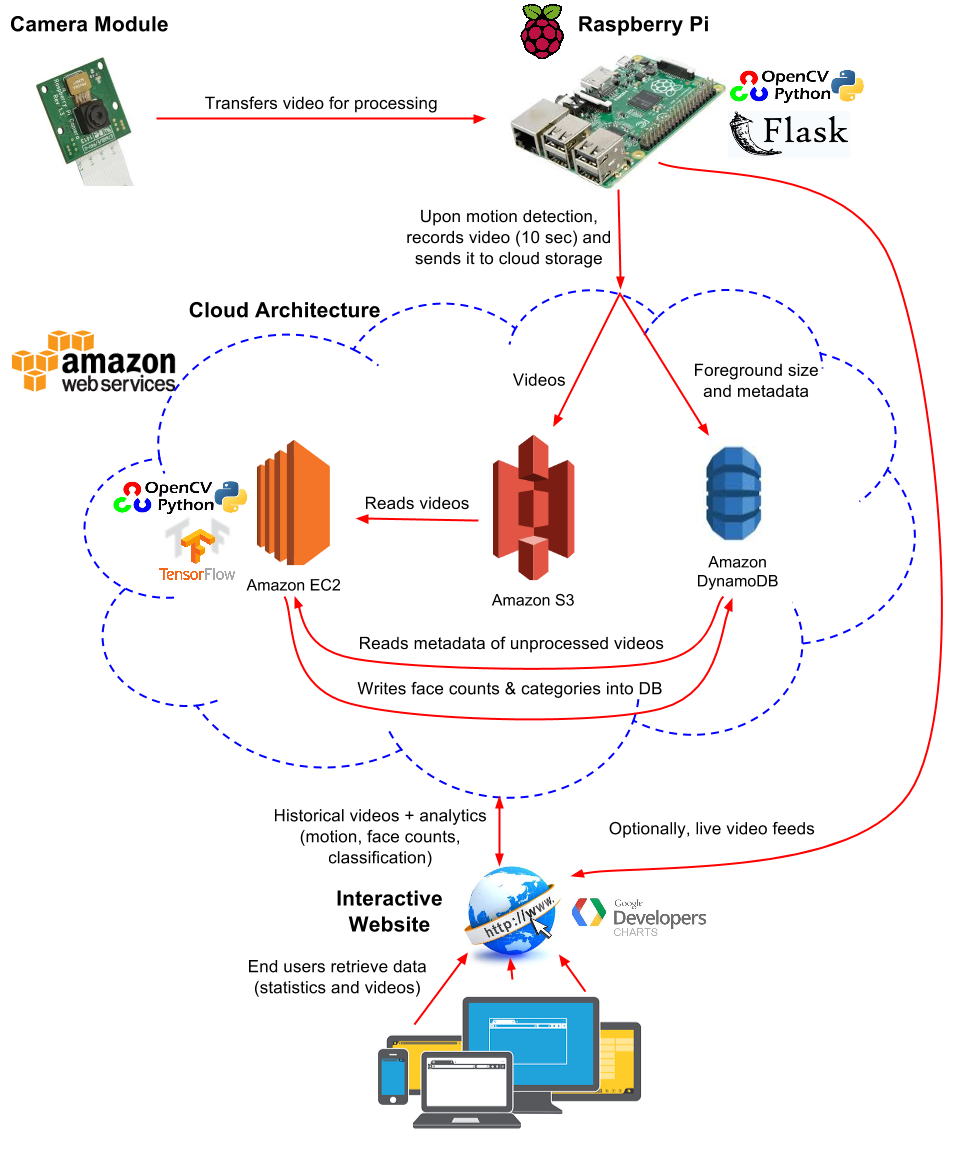
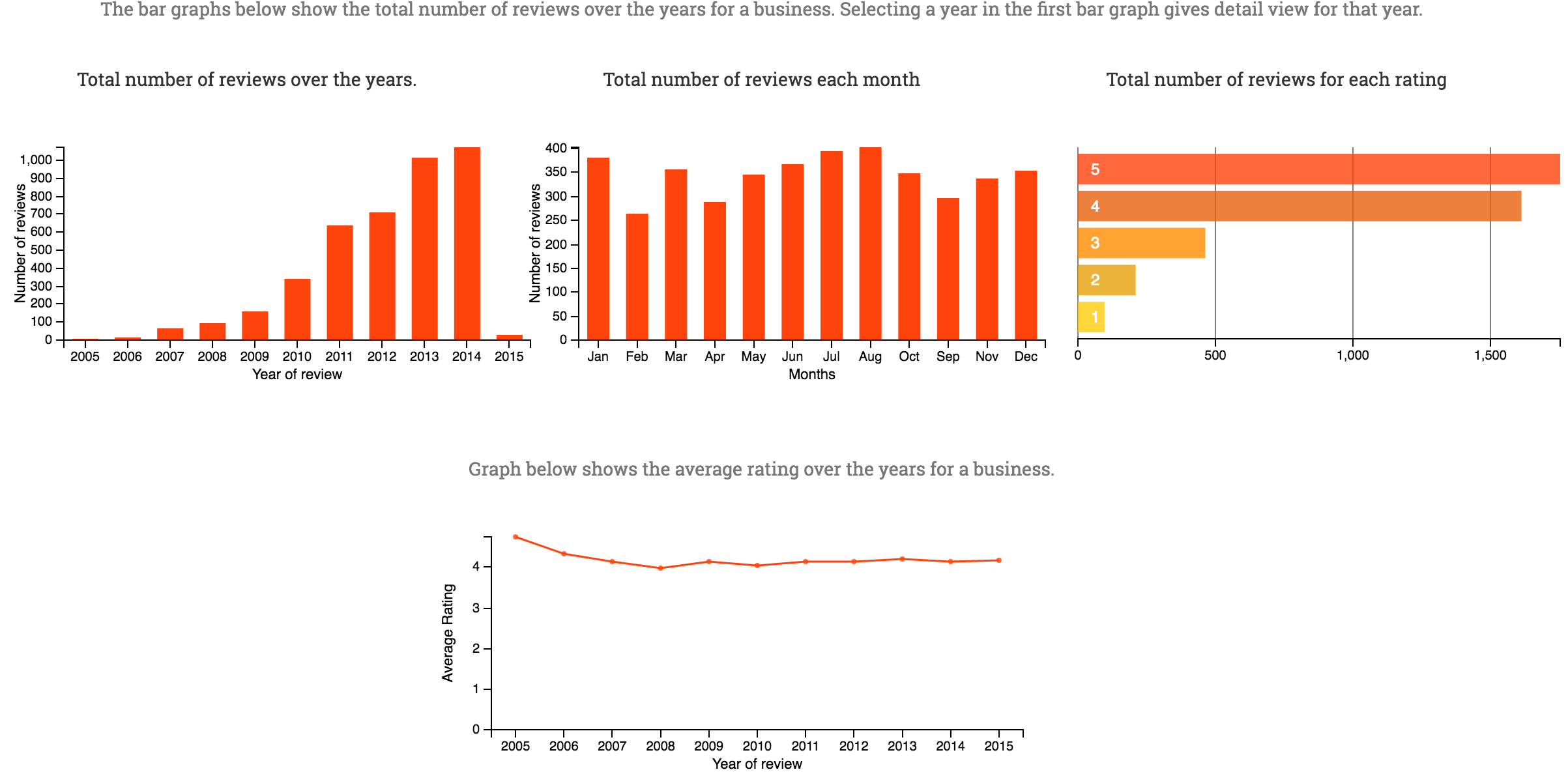
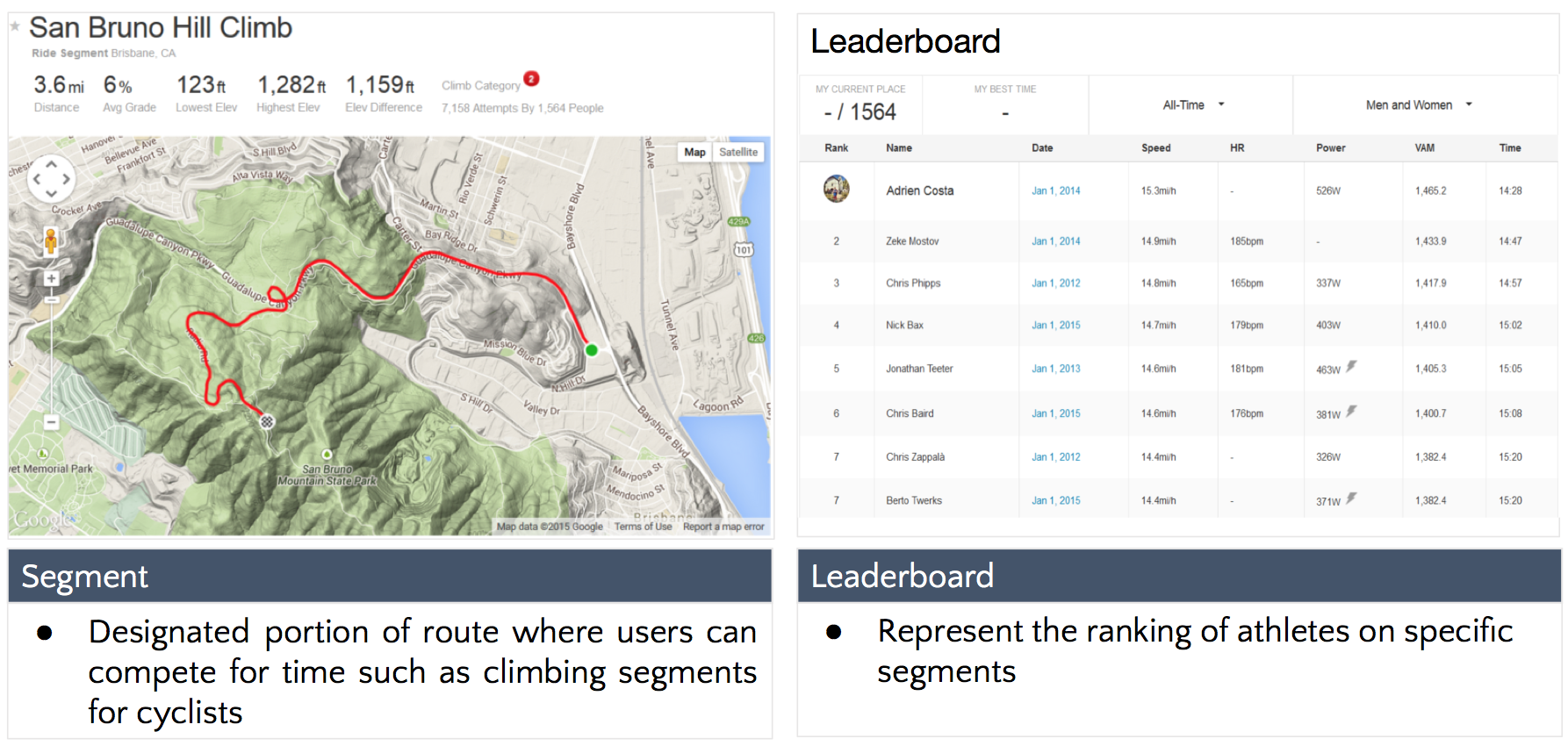
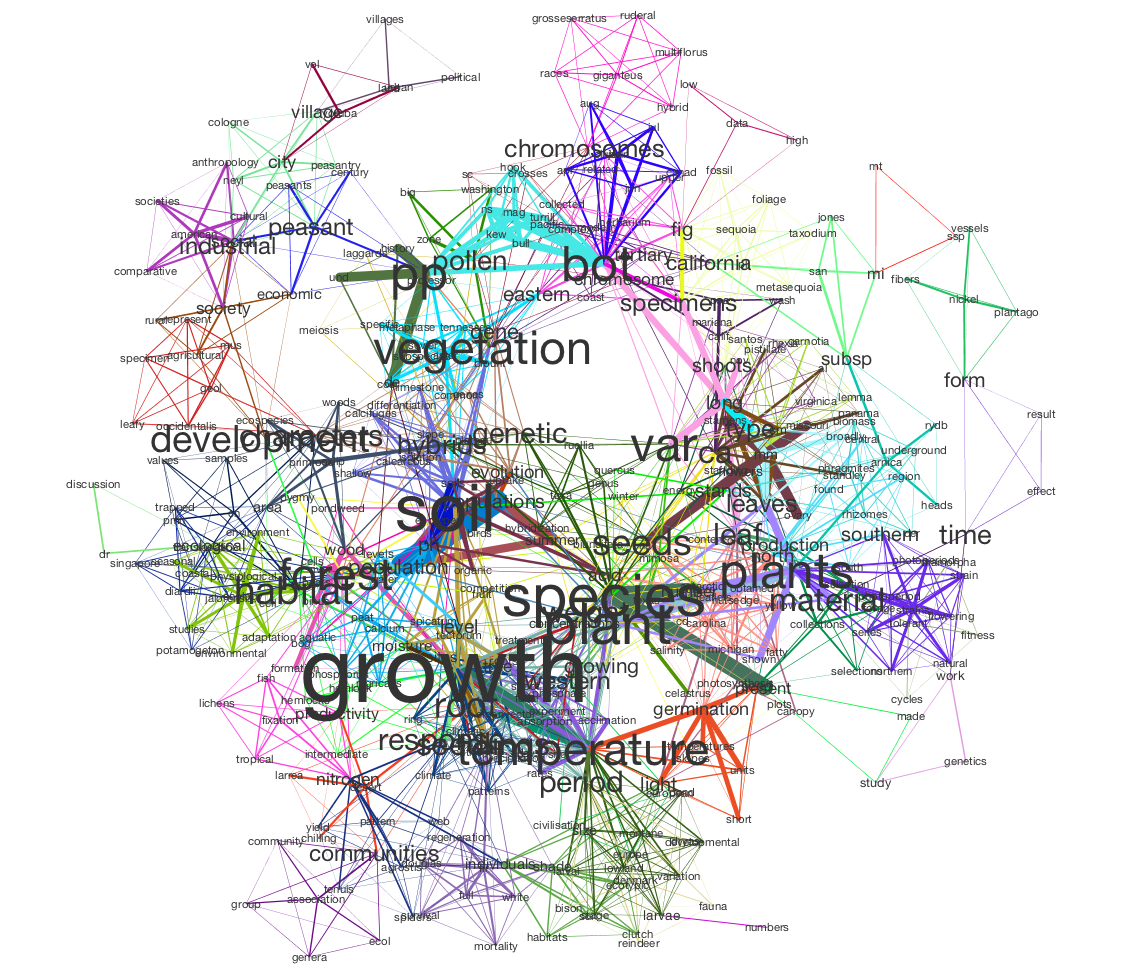
An aspiring Data Scientist / Engineer with a background in software development & testing, I am most passionate about solving problems in the intersection of technology, science, and domain, with newly acquired skills, an insatiable intellectual curiosity, and the ability to uncover patterns from large data sets.
I always believed if there were a career, which could integrate my engineering and programming background with my interest in Mathematics, Statistics, and Technology then that would be the career I would be most happy pursuing; Data Science seemed to fit my criteria from all angles & drove me to pursue a part-time Masters program in Information and Data Science (MIDS 2016) from UC Berkeley School of Information, where I graduated from recently.
A strong believer of continuous education, and eager & curious to keep up with the latest advances in this ever changing landscape of Data Science / Artifical Intelligence, I constantly try to keep myself up to date by taking courses, reading research papers, or simply playing with some data set just to have some fun!
In my spare time, I play (and watch) soccer and cricket (Indian version of Baseball, only better!). Love hiking, traveling, leisure reading, and off late trying my hand at digital photography.